问题
最近在黑石上测试提交了一个webserver的app,发现无法访问其中一个pod的webserver的端口,但是pod的IP 10.2.1.15可以ping通。
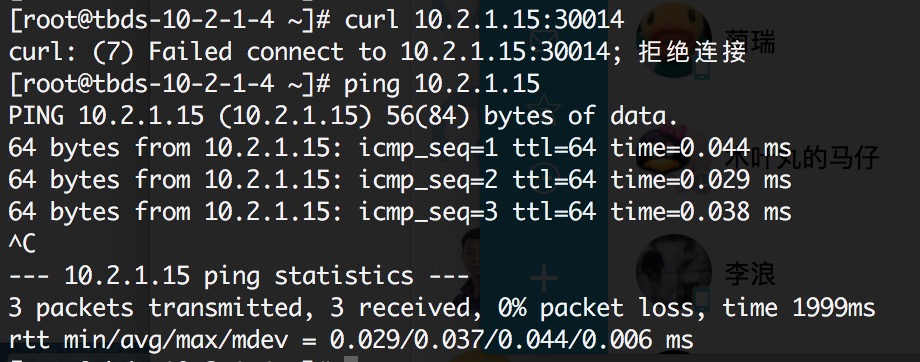
在容器中却可以正常访问这个端口。
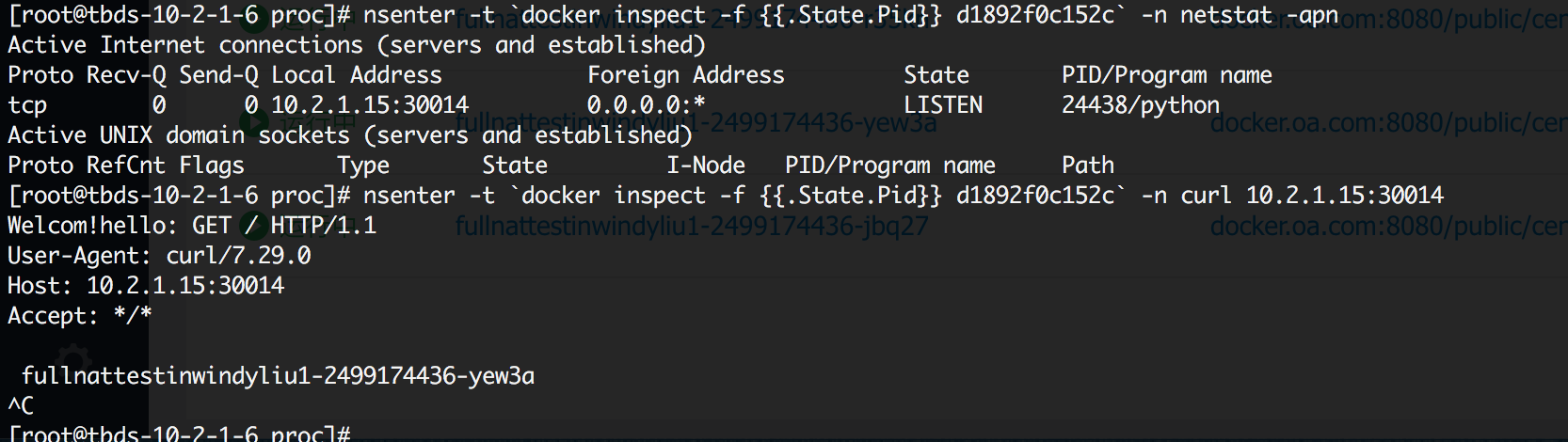
查看了容器所在主机10.2.1.6上的iptables规则,并没有限制这个ip和端口的访问。
经查发现能ping通10.2.1.15而不能访问端口是因为报文发送到了另外一台10.2.1.4机器上,而不是pod所在主机10.2.1.6。
对每个桥接到docker网桥上的veth网卡进行抓包分析,发现报文发给了veth-hb786fa8网卡。

问题排查
初步怀疑是网络空间没有删除导致。由于veth-hb786fa8网卡的名称是自研的CNI插件随机生成的,与容器的id没有关系,所以通过名称无法判断是哪个容器。尝试了多种方法无法分析出10.2.1.15所在的网络空间
-
进入所有进程的network namespace,查询10.2.1.15的ip,无法查到
cd /proc; for i in `ls -d */ | grep “^[1-9]”`; do has=`nsenter –net=/proc/${i}ns/net ip ad | grep 10.2.1.15`; if [ “$has” != “” ]; then echo “$i has ip”; fi ; done
-
通过docker创建的网络空间句柄进入所有docker创建的网络空间,无法查到(进入某些网络空间句柄时报错
nsenter: 重新关联到名字空间“ns/net”失败: 无效的参数)cd /var/run/docker/netns; for i in ls; do nsenter –net=$i ip adgrep 10.2.1.15; done
查到这里有些没有头绪,我可以肯定这个ip一定配置在了某个网络空间中,但是上面的方法为什么查不到这个ip,不应该呀?之前一直对nsenter: 重新关联到名字空间“ns/net”失败: 无效的参数这个报错有些疑问,认为是内核的某个BUG,但是后面发现问题后才知道是操作有问题。
通过10.2.1.15 IP grep了10.2.1.4机器上CNI网络插件的日志,发现最后一个使用10.2.1.15的容器是326383b80aba6e0ab7774f98ae36e1308cfd1d6165372222c4358b72534dee44,所以10.2.1.15很可能还配置在这个容器的网络空间中
I0206 12:22:17.639674 27084 server.go:81] ADD loadbalancenatwindyliu-2396807556-ure36_demo, 326383b80aba6e0ab7774f98ae36e1308cfd1d6165372222c4358b72534dee44, /proc/5145/ns/net, Ig noreUnknown=1;K8S_POD_NAMESPACE=demo;K8S_POD_NAME=loadbalancenatwindyliu-2396807556-ure36;K8S_POD_INFRA_CONTAINER_ID=326383b80aba6e0ab7774f98ae36e1308cfd1d6165372222c4358b72534dee44 ;, data {"ip4":{"ip":"10.2.1.15/24","gateway":"10.2.1.1","routes":[{"dst":"0.0.0.0/0"}]},"dns":{}}, err <nil>, Feb 6 12:22:16.970597-
这个容器处于Dead状态,容器进程已经结束,应该是容器删除失败了,也查询不到网络空间的文件句柄

创建网络空间
既然是网络空间没有删除,先回顾下docker中网络空间的创建,代码在namespace_linux.go中
func createNetworkNamespace(path string, osCreate bool) error {
if err := createNamespaceFile(path); err != nil {
return err
}
cmd := &exec.Cmd{
Path: reexec.Self(),
Args: append([]string{"netns-create"}, path),
Stdout: os.Stdout,
Stderr: os.Stderr,
}
if osCreate {
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.SysProcAttr.Cloneflags = syscall.CLONE_NEWNET
}
if err := cmd.Run(); err != nil {
return fmt.Errorf("namespace creation reexec command failed: %v", err)
}
return nil
}
func init() {
reexec.Register("netns-create", reexecCreateNamespace)
}
func reexecCreateNamespace() {
if len(os.Args) < 2 {
log.Fatal("no namespace path provided")
}
if err := mountNetworkNamespace("/proc/self/ns/net", os.Args[1]); err != nil {
log.Fatal(err)
}
}
func mountNetworkNamespace(basePath string, lnPath string) error {
if err := syscall.Mount(basePath, lnPath, "bind", syscall.MS_BIND, ""); err != nil {
return err
}
if err := loopbackUp(); err != nil {
return err
}
return nil
}
可以看到,docker以CLONE_NEWNET参数启动了一个子进程,子进程将自己的/proc/self/ns/net mount到一个path(比如/var/run/docker/netns/57c3e1e0fea7)上,然后子进程退出
func nsInvoke(path string, prefunc func(nsFD int) error, postfunc func(callerFD int) error) error {
defer InitOSContext()()
f, err := os.OpenFile(path, os.O_RDONLY, 0)
if err != nil {
return fmt.Errorf("failed get network namespace %q: %v", path, err)
}
defer f.Close()
nsFD := f.Fd()
// Invoked before the namespace switch happens but after the namespace file
// handle is obtained.
if err := prefunc(int(nsFD)); err != nil {
return fmt.Errorf("failed in prefunc: %v", err)
}
if err = netns.Set(netns.NsHandle(nsFD)); err != nil {
return err
}
defer ns.SetNamespace()
// Invoked after the namespace switch.
return postfunc(ns.ParseHandlerInt())
}
实际要在network namespace中进行网络配置时调用setns系统调用进入network namespace
看完这部分代码我们了解到docker创建的network namespace是可以脱离进程存在的,我们可以写点代码模拟下
# unshare -n /bin/bash
# ip ad
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
# ip link add mytestif type dummy
# ip ad
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: mytestif: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether da:fe:45:83:55:b6 brd ff:ff:ff:ff:ff:ff
# mount --bind /proc/self/ns/net /run/mynetns
# exit
exit
# nsenter --net=/run/mynetns ip ad
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: mytestif: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether da:fe:45:83:55:b6 brd ff:ff:ff:ff:ff:ff
unshare -n /bin/bash以CLONE_NEWNET启动一个新的网络空间的bash进程,网络空间中只有lo设备,创建一个dummy的网卡作为这个网络空间的标识,mount bash进程自己的网络空间句柄到/run/mynetns,之后退出bash进程。用nsenter使用/run/mynetns文件作为网络空间句柄启动一个ip进程,从输出我们可以看出bash退出后网络空间并没有释放,之前创建的网卡还存在。
# cat /proc/mounts | grep mynetns
nsfs /run/mynetns nsfs rw 0 0
# umount /run/mynetns
# nsenter --net=/run/mynetns ip ad
nsenter: 重新关联到名字空间“ns/net”失败: 无效的参数
查看mount的设备,我们能看到/run/mynetns mount成了nsfs文件系统(3.19内核前会mount成proc文件系统),umount /run/mynetns后,我们创建的网络空间就删除了。
如何找到没有进程存在的网络空间
从上面的过程我们可以想到从/proc/mounts中找到所有的nsfs mountpoint再进入网络空间不就行了?实际执行后仍然没有找到10.2.1.15的IP。哪里出了问题?
联想到docker daemon启动后会进入新的mount namespace(docker.service文件中增加的MountFlags=slave)所以应该从docker daemon的mount namespace中查找所有nsfs的mountpoint,依然找不到10.2.1.15。
观察docker daemon的启动时间,发现某些容器是docker daemon启动前就运行的(自研的docker daemon热升级功能,拉起容器时进程树变成三级结构,docker daemon进程启动子进程docker_monitor,docker_monitor再启动并等待容器子进程)
docker daemon重启后,由于docker daemon是其他所有docker_monitor进程的父进程并且mountFlags=slave,docker daemon配置的所有mount引用传递给所有的docker_monitor进程,即docker_monitor进程会持有所有容器的mount引用(包括mount的容器文件系统,shm,netns)
于是找到一个docker daemon重启前启动的docker_monitor进程的pid(父进程为1的docker_monitor进程),先进入这个docker_monitor进程的mount namespace,再进入网络空间
# nsenter -t 8581 -m nsenter --net=/var/run/docker/netns/cf51d21b4b4e ip ad
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN
link/ipip 0.0.0.0 brd 0.0.0.0
inet 115.159.246.146/32 brd 115.159.246.146 scope global tunl0:0
valid_lft forever preferred_lft forever
3: tunl1@eth0: <POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1480 qdisc noqueue state UNKNOWN
link/ipip 10.2.1.15 peer 100.80.72.130
inet 127.0.1.1/32 scope host tunl1
valid_lft forever preferred_lft forever
4032: eth0@if4033: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP
link/ether 02:42:0a:02:01:0f brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.2.1.15/24 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:aff:fe02:10f/64 scope link tentative dadfailed
valid_lft forever preferred_lft forever
遍历所有docker创建的文件句柄发现了10.2.1.15。
总结
复现方式:
- docker开启热升级功能,docker的systemd service配置文件中增加mountFlags=slave
- 以–net=none方式启动两个容器,给两个容器手动配置fixip网络(必须手动配置,不能使用docker的网络模式)
- 重启docker daemon
- docker rm -vf删除其中一个容器 观察被删除容器,发现网卡和网络空间未被删除。
- 删除另外一个容器,发现两个容器的网络空间和网卡均被删除
原因:
- docker daemon开启热升级后,拉起容器时进程树变成三级结构,docker daemon进程启动子进程docker_monitor,docker_monitor再启动并等待容器子进程
- 增加mountFlags=slave时,docker daemon进程启动后进入新的mount namespace(这么做的目的是:docker daemon 新创建的mount对主机的其他进程不可见,即其他进程不会持有docker daemon mount操作的引用)
- docker daemon重启后,由于docker daemon是其他所有docker_monitor进程的父进程并且mountFlags=slave,docker daemon配置的所有mount引用传递给所有的docker_monitor进程,即docker_monitor1会持有所有容器的mount引用(包括mount的容器文件系统,shm,netns)
- 删除一个容器时,这个容器的mount引用被其他docker_monitor进程持有,所以网络空间不能被释放。
- 只有删除所有daemon重启前的其他容器后,mount引用被删除才会释放网络空间
- 重现步骤中必须手动配置网络模式是因为docker daemon在删除网络空间前会删除docker自己配置的网卡
解决方法:
去掉mountFlags=slave
查找所有网络空间:
# find all namespaces which have a process in it.
readlink /proc/*/ns/* | sort -u
# enter the namespace
nsenter --mount=/proc/19877/ns/net bash
# find all namespaces which have no processes in it.
# awk '$9 == "proc" {print FILENAME,$0}' /proc/*/mountinfo | sort -k2 -u (kernel < 3.19)
awk '$9 == "nsfs" {print FILENAME,$0}' /proc/*/mountinfo | sort -k2 -u
# enter the namespace
nsenter --mount=/proc/19877/ns/mnt -- nsenter --net=/run/mynetns true