背景
当前有一些团队想使用docker做开发测试,很多测试场景是多个app共享一个数据库,app和数据库可能在不同的机器上。
- Docker原生提供的bridge模式可以通过映射的方式访问不同主机上的container,但是这种模式依赖iptable_nat模块,而tlinux2.0默认不带这个模块。并且bridge模式需要修改端口配置。
- 可以使用pipework给container分配一个内网的ip,但是内网ip有限
docker 1.9.1 overlay网络的问题
Docker在1.9.1提供了overlay网络的实现,但是这个实现有两个限制
- 内核版本大于等于3.16
- docker默认会给使用overlay网络的container增加一个bridge模式的网关,所以依赖于iptable_nat模块
第1个问题,docker公司已经解决。
第2个问题,其实并不是所有接入overlay网络的container都需要访问外部网络,某些container能访问外部网络即可。针对上面的应用场景,我们完全可以将部分主机接入这个由container组成的私有网络,作为整个网络的入口。
笔者给docker/libnetwork贡献了一些patch,在使用docker network create创建overlay网络时,增加一个开关,创建完全与外界网络隔离的overlay网络,代码详见 https://github.com/docker/libnetwork/pull/831 ,这样使用overlay网络可以完全不依赖iptable_nat模块
使用
1.下载最新版的docker二进制包。
internal参数并没有在1.9.1版本发布,如果要使用请编译master分支最新的docker
2.修改docker daemon配置,配置共享存储。
--cluster-store=zk://127.0.0.1:2181 --cluster-advertise=eth1:2376
3.拉起container加入私有网络
# 在其中一台机器上创建一个overlay网络
$ docker network create --internal -d overlay --subnet=192.1.0.0/16 overlay
# 分别在两台机器上运行一个container并加入overlay网络
$ docker run --net=overlay -d docker.oa.com:8080/gaia/helloworld
# 测试两个container能否相互访问
$ docker exec `docker ps -q` ping -c 3 192.1.0.3
PING 192.1.0.3 (192.1.0.3) 56(84) bytes of data.
64 bytes from 192.1.0.3: icmp_seq=1 ttl=64 time=0.194 ms
64 bytes from 192.1.0.3: icmp_seq=2 ttl=64 time=0.187 ms
64 bytes from 192.1.0.3: icmp_seq=3 ttl=64 time=0.159 ms
--- 192.1.0.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.159/0.180/0.194/0.015 ms
创建overlay网络时–subnet可以任意设置有效的ip段,但是如果与本机的路由或者是DNS server配置有ip冲突,在将container接入网络时会报错 “Error response from daemon: subnet sandbox join failed for “10.0.0.0/24”: overlay subnet 10.0.0.0/24 has conflicts in the host while running in host mode.”
至此我们创建好了一个与外界隔离的overlay网络,网络中的container可以相互访问 这部分可以完全参考docker公司的文档
配置与外界网络的访问
配置与外界的访问有多种选择,这里只介绍两种
配置一个主机与加入overlay网络
先介绍怎么配置,后面的篇幅介绍原理。比如现在其中一个container运行在10.0.0.2,我们想要将另一台主机10.0.0.1接入这个overlay的网络
1.在10.0.0.1上创建vxlan device,分配给vxlan的ip 192.1.0.255请不要与container的ip重复
$ ip link add vxlan0 type vxlan id 256 dev eth1 dstport 4789
$ ip ad add 192.1.0.255/16 dev vxlan0
$ ip link set dev vxlan0 up
2.在10.0.0.1上配置ARP和二层转发表
vxlan_dev=vxlan0 #10.0.0.1上创建的vxlan设备的名称
container_mac=02:42:c0:01:00:03 #container网卡的mac地址
container_ip=192.1.0.3 #container的ip地址
peer_host_ip=10.0.0.2 #container所在主机的ip地址
$ ip neigh add $container_ip lladdr $container_mac dev $vxlan_dev nud permanent
$ bridge fdb add to $container_mac dst $peer_host_ip dev $vxlan_dev
3.在10.0.0.2上配置ARP和二层转发表
vxlan_dev=vx-000100-bfbc7 #10.0.0.2上docker创建的vxlan设备的名称
peer_vxlan_mac=ee:98:24:23:11:7b #10.0.0.1上我们创建的vxlan设备的mac地址
peer_vxlan_ip=192.1.0.255 #10.0.0.1上我们创建的vxlan设备的ip地址
peer_host_ip=10.0.0.1
# 3.10的内核,vxlan设备创建在host的network namespace
$ ip neigh add $peer_vxlan_ip lladdr $peer_vxlan_mac dev $vxlan_dev nud permanent
$ bridge fdb add to $peer_vxlan_mac dst $peer_host_ip dev $vxlan_dev
4.尝试在10.0.0.1上访问container的ip
$ ping -c 3 192.1.0.3
PING 192.1.0.3 (192.1.0.3) 56(84) bytes of data.
64 bytes from 192.1.0.3: icmp_seq=1 ttl=64 time=0.146 ms
64 bytes from 192.1.0.3: icmp_seq=2 ttl=64 time=0.131 ms
64 bytes from 192.1.0.3: icmp_seq=3 ttl=64 time=0.125 ms
--- 192.1.0.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 0.125/0.134/0.146/0.008 ms
配置其中一个container加入bridge网络
我们也可以将其中一个container加入bridge网络,也可以与外界相互访问
$ docker network connect bridge 69122fa5bd9a
$ docker exec -it 69122fa5bd9a bash
root@69122fa5bd9a:/# ip ad
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
13797: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UP group default
link/ether 02:42:c0:01:00:03 brd ff:ff:ff:ff:ff:ff
inet 192.1.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::42:c0ff:fe01:3/64 scope link
valid_lft forever preferred_lft forever
13803: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:c0:a8:01:02 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.2/24 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::42:c0ff:fea8:102/64 scope link
valid_lft forever preferred_lft forever
vxlan原理
vxlan协议
vxlan协议是一个隧道协议,设计出来是为了解决vlan id (只有4096个)不够用的问题。vxlan id有24个字节,最多可以支持16777216个隔离的vxlan网络。
vxlan将以太网包封装在UDP中,并使用物理网络的ip/mac作为outer-header进行封装,然后在物理网络上传输,到达目的地后由隧道终结点解封并将数据发送给目标,vxlan协议的表头如下
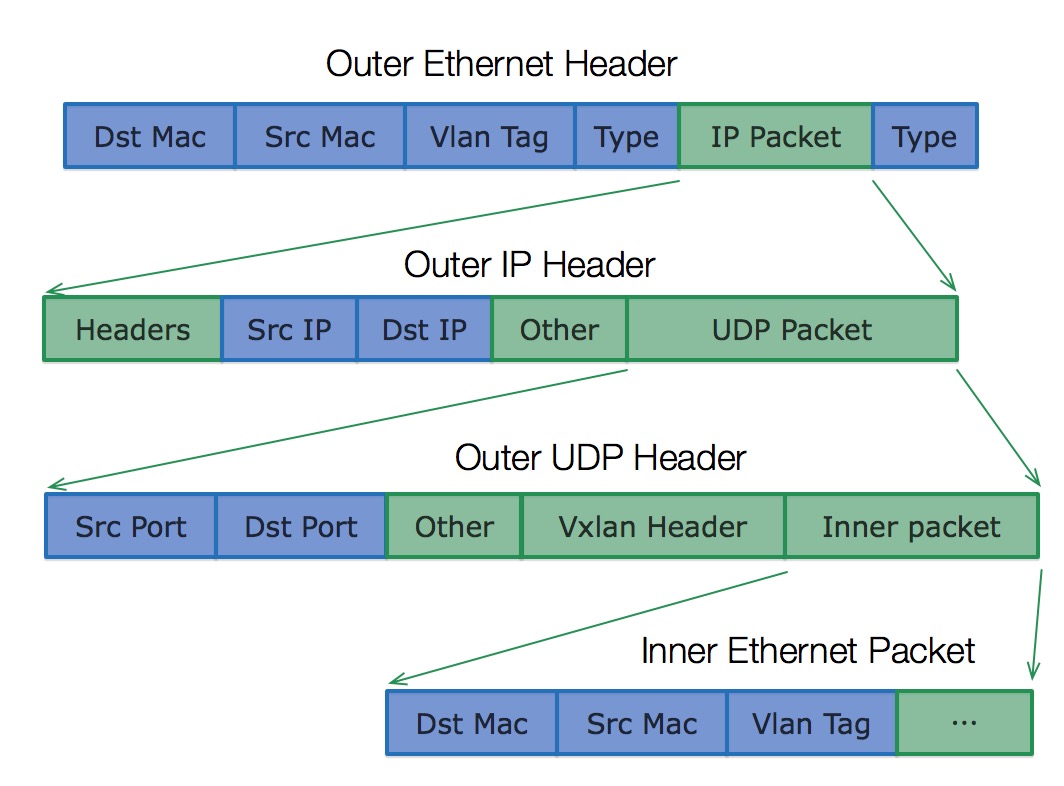
既然vxlan将以太网包封装在UDP中,如果想访问vxlan网络中的一个ip地址(上图中的inner dst ip),这里就有两个问题需要解决:
- 如何知道inner dst mac?
- 如何知道inner dst mac所在地址(outer dst ip)?
下面就以上面介绍的配置一个主机加入overlay网络这个例子来解释这两个问题的解决
ARP表和FDB表
先解释一下ARP表和FDB(二层转发表)表
ARP表都比较熟悉,它是由3层设备(路由器,三层交换机,服务器,电脑)用来存储ip地址和mac地址对应关系的一张表,而二层转发表可能比较陌生,它是由2层设备(二层交换机)用来存储mac地址和端口对应关系的一张表,使得交换机知道哪些mac地址连接在哪些端口上。
看下面的一张图,一个二层交换机连接两台PC,在PC1上ping PC2时,会发生ARP广播解析PC2的mac地址,PC1会记录PC2的ip和mac对,交换机见证了ARP的整个过程,会记录下每个端口的mac地址
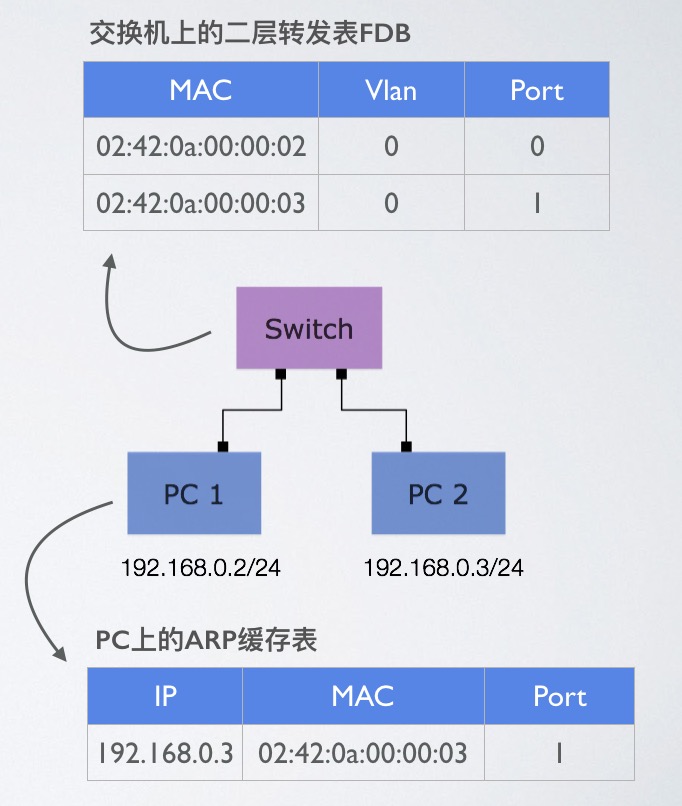
这里也有一篇文章介绍得很清楚 https://blog.michaelfmcnamara.com/2008/02/what-are-the-arp-and-fdb-tables/
linux vxlan设备的实现
要解决第1个问题 “如何知道inner dst mac?”,ARP表就可以记录ip和mac的对应关系,所以在前面讲到的配置一个主机加入overlay网络中提到会手动配置一条ARP记录 ip neigh add $peer_vxlan_ip lladdr $peer_vxlan_mac dev $vxlan_dev nud permanent
要解决第2个问题 “如何知道inner dst mac所在地址(outer dst ip)?”,需要一个表记录inner dst mac <=> outer dst ip的对应关系,vxlan设备的FDB表就是用来记录这个对应关系,如上述操作 bridge fdb add to $peer_vxlan_mac dst $peer_host_ip dev $vxlan_dev 。
linux vxlan设备的FDB表与上文提到的交换机的FDB表略不同:交换机的FDB表保存是mac地址与交换机端口的对应关系,vxlan设备的FDB表保存的是mac地址与outer dst ip的对应关系。outer dst ip其实就是vxlan隧道端点的地址(VXLAN Tunnel End Point简称VTEP)。所以也可以说vxlan设备的FDB表保存的是mac地址与VTEP端的对应关系。
理解了这一点其实也明白了为什么vxlan其实是一个一对多的网络(因为一个vxlan设备可以配置多个目的VTEP地址),a VXLAN is a 1 to N network, not just point to point(https://www.kernel.org/doc/Documentation/networking/vxlan.txt) 这也是vxlan协议较GRE协议的一个优势。
docker overlay网络的实现
接下来我们来看docker给container配置的overlay网络结构,下图就是docker创建的overlay网络(这里画的是>=3.16的内核,docker会创建overlay的namespace,<3.16的内核因为vxlan设备不支持NETIF_F_NETNS_LOCAL属性,所以没有创建overlay的namespace)
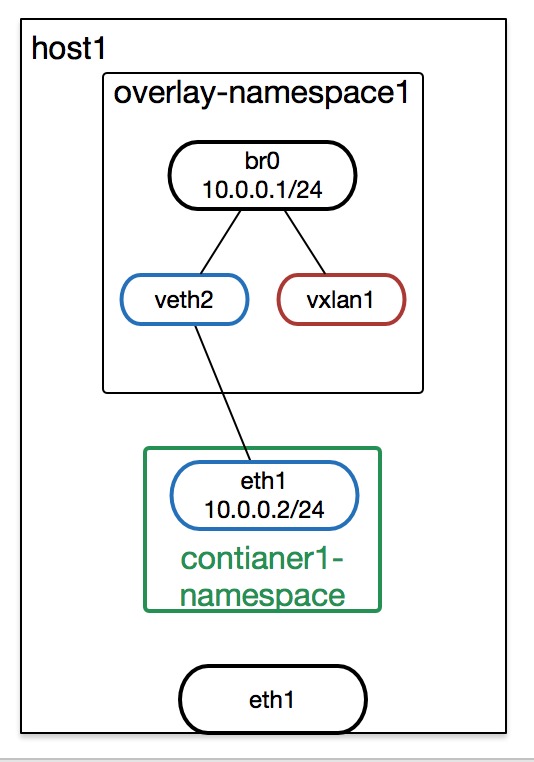
docker给创建的每一个overlay network创建一个network namespace(图中的overlay-namespace1),将vxlan设备(图中的vxlan1)移入这个network namespace,并连接一个bridge设备(图中的br0),container的namespace与vxlan设备的namespace通过veth设备连接(图中的veth2 eth1是一对veth设备),veth设备的一端(veth2)接入bridge设备
在container中访问与container同网段的ip,比如10.0.0.3时,数据包就会通过veth设备传播到vxlan设备所在的namespace,然后通过ARP表查询出10.0.0.3的mac地址,然后通过vxlan设备的FDB表查询出VTEP的地址,完成封包,并经过udp socket发送包。
<3.16的内核docker直接将vxlan1 br0 veth2创建在了global namespace中。由于network device/socket/ARP表/FDB表/路由表都是被namespace隔离的,显然这里将vxlan设备放入一个独立的namespace中的好处是可以支持多个overlay network使用相同的虚拟ip段。<3.16的内核就无法创建相同的ip段的overlay网络了。
docker的实现主要是两点:
- 使用高一致性的共享存储zk/etcd/consul保存创建的overlay网络(docker network create)元数据(vxlan id,ip段,已经使用的ip)
- 使用了第三方的一个去中心化的服务发现组件serf去做ip, mac, VTEP ip对的同步。有container加入或者离开网络时,通知有相关VTEP上的docker daemon更新ARP表和FDB表
除了依赖serf去做主动同步,docker还使用了vxlan设备DOVE extensions(Distributed Overlay Virtual Ethernet)的一些特性
- L3MISS 如果在ARP表中找不到目的ip地址对应的mac地址,将消息通过内核的netlink机制发送到用户态,期望用户态监听并补充ARP记录
- L2MISS 如果在vxlan的FDB表中找不到目的mac地址对应的VTEP地址,将消息通过内核的netlink机制发送到用户态,期望用户态监听并补充FDB表
docker daemon监听了这些消息,这样在内核找不到ARP或者FDB记录时,docker daemon通过serf去查询。
func (n *network) watchMiss(nlSock *nl.NetlinkSocket) {
for {
msgs, err := nlSock.Receive()
if err != nil {
logrus.Errorf("Failed to receive from netlink: %v ", err)
continue
}
for _, msg := range msgs {
if msg.Header.Type != syscall.RTM_GETNEIGH && msg.Header.Type != syscall.RTM_NEWNEIGH {
continue
}
neigh, err := netlink.NeighDeserialize(msg.Data)
if err != nil {
logrus.Errorf("Failed to deserialize netlink ndmsg: %v", err)
continue
}
if neigh.IP.To16() != nil {
continue
}
if neigh.State&(netlink.NUD_STALE|netlink.NUD_INCOMPLETE) == 0 {
continue
}
mac, IPmask, vtep, err := n.driver.resolvePeer(n.id, neigh.IP)
if err != nil {
logrus.Errorf("could not resolve peer %q: %v", neigh.IP, err)
continue
}
if err := n.driver.peerAdd(n.id, "dummy", neigh.IP, IPmask, mac, vtep, true); err != nil {
logrus.Errorf("could not add neighbor entry for missed peer %q: %v", neigh.IP, err)
}
}
}
}
笔者对照docker daemon的代码,写了一个完整的配置上述overlay网络的脚本,有兴趣的可以看一下
vxlan设备如何将数据包发送到主机的global namespace
这里有一个问题,由于socket是被namespace隔离的,那么vxlan设备如何将封包后的数据包发送到global namespace?因为最终是会通过global namespace的物理网卡将包发送出去
如果想要两个network namespace相互访问,只有两种办法:1.使用veth设备连接两个namespace 2.使用unix socket进行通信 vxlan设备没有使用上面两种办法,又是如何做到的?
看过kernel中vxlan的代码之后,然来这只是内核态代码的一个trick,因为vxlan device对象保存了一个创建设备时namespace的指针,所以vxlan设备在内核态创建的udp socket server实际还是在global namespace监听请求,所以vxlan设备可以在一个namespace中接收包,然后发送到global namespace。具体内核代码如下
drivers/net/vxlan.c
static int vxlan_dev_configure(struct net *src_net, struct net_device *dev,
struct vxlan_config *conf)
{
...
vxlan->net = src_net; //保存创建vxlan设备时的原net namespace的指针
...
}
static int vxlan_open(struct net_device *dev)
{
struct vxlan_dev *vxlan = netdev_priv(dev);
struct vxlan_sock *vs;
vs = vxlan_sock_add(vxlan->net, vxlan->cfg.dst_port,
vxlan->cfg.no_share, vxlan->flags);
...
}
static struct socket *vxlan_create_sock(struct net *net, bool ipv6,
__be16 port, u32 flags)
{
...
/* Open UDP socket */
err = udp_sock_create(net, &udp_conf, &sock); //在原net namespace创建udp socket
...
}
ip组播
docker实际是通过静态配置ARP表和FDB表解决了发现VTEP的问题,其实ip组播也可以解决发现VTEP的问题。
在创建vxlan设备时,指定组播ip地址ip link add vxlan0 type vxlan id 42 group 239.1.1.1 dev eth1 dstport 4789,vxlan设备封包时将outer dst ip地址写为组播地址239.1.1.1,其他所有主机的vxlan设备收到组播后回复
下面的tcpdump报文就是组播解决VTEP的过程,主机1(ip 192.168.33.11, mac 08:00:27:f8:73:79),主机2(ip 192.168.33.12, mac 08:00:27:d9:18:aa)
# set up on host1 192.168.33.11, 08:00:27:f8:73:79
ip link add vxlan0 type vxlan id 42 group 239.1.1.1 dev eth1 dstport 4789
ip link set vxlan0 address 54:8:20:0:0:1
ip address add 10.0.0.1/8 dev vxlan0
ip link set up vxlan0
# set up on host2 192.168.33.12, 08:00:27:d9:18:aa
ip link add vxlan0 type vxlan id 42 group 239.1.1.1 dev eth1 dstport 4789
ip link set vxlan0 address 54:8:20:0:0:2
ip address add 10.0.0.2/8 dev vxlan0
ip link set up vxlan0
tcpdump -n -s 0 -e -i eth1 -v "icmp or arp or udp"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on vxlan0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:24:14.345289 08:00:27:f8:73:79 > 01:00:5e:01:01:01, ethertype IPv4 (0x0800), length 92: (tos 0x0, ttl 1, id 41644, offset 0, flags [none], proto UDP (17), length 78)
192.168.33.11.38762 > 239.1.1.1.4789: VXLAN, flags [I] (0x08), vni 42
54:08:20:00:00:01 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Request who-has 10.0.0.2 tell 10.0.0.1, length 28
16:24:14.345376 08:00:27:d9:18:aa > 08:00:27:f8:73:79, ethertype IPv4 (0x0800), length 92: (tos 0x0, ttl 64, id 37324, offset 0, flags [none], proto UDP (17), length 78)
192.168.33.12.46410 > 192.168.33.11.4789: VXLAN, flags [I] (0x08), vni 42
54:08:20:00:00:02 > 54:08:20:00:00:01, ethertype ARP (0x0806), length 42: Ethernet (len 6), IPv4 (len 4), Reply 10.0.0.2 is-at 54:08:20:00:00:02, length 28
16:24:14.345632 08:00:27:f8:73:79 > 08:00:27:d9:18:aa, ethertype IPv4 (0x0800), length 148: (tos 0x0, ttl 64, id 2877, offset 0, flags [none], proto UDP (17), length 134)
192.168.33.11.52130 > 192.168.33.12.4789: VXLAN, flags [I] (0x08), vni 42
54:08:20:00:00:01 > 54:08:20:00:00:02, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 17819, offset 0, flags [DF], proto ICMP (1), length 84)
10.0.0.1 > 10.0.0.2: ICMP echo request, id 2475, seq 1, length 64
16:24:14.345694 08:00:27:d9:18:aa > 08:00:27:f8:73:79, ethertype IPv4 (0x0800), length 148: (tos 0x0, ttl 64, id 37325, offset 0, flags [none], proto UDP (17), length 134)
192.168.33.12.43948 > 192.168.33.11.4789: VXLAN, flags [I] (0x08), vni 42
54:08:20:00:00:02 > 54:08:20:00:00:01, ethertype IPv4 (0x0800), length 98: (tos 0x0, ttl 64, id 51311, offset 0, flags [none], proto ICMP (1), length 84)
10.0.0.2 > 10.0.0.1: ICMP echo reply, id 2475, seq 1, length 64
组播的方式由于需要IGMP,对于物理交换机和路由器需要做一些配置,并且也不适合网络上距离较远的场景,一般不会使用这种方式
##结束语
当然Overlay网络不仅限与上面的应用场景,这里只是抛砖引玉,期待挖掘更多的应用场景
##参考
Virtual eXtensible Local Area Network (VXLAN)