最近看到0.12版hive中的一个优化Hive Correlation Optimizer,小感慨一下
关于作者YIN HUAI
俄亥俄州立大学 phd 个人简介 http://www.cse.ohio-state.edu/~huai/
关于Hive Correlation Optimizer
出自YIN HUAI与其在大学的老师和同学的一篇论文 YSmart: Yet another SQL-to-MapReduce Translator (见个人简介)
论文的核心思想是:当前有很多可以将SQL转化为MapReduce job的引擎,如hive/pig。这些引擎极大的提高了编写MR程序的效率,但是这些引擎生成的MR程序对于多少查询的运行效率却不如手写的MR程序。
论文中提出一种优化方法,找到SQL生成的MR Job DAG中重复使用的表,减少重复读取,找到DAG中前后两个拥有相同shuffle key的Job,减少不必要的shuffle,合并MR job,达到减少计算量、减少I/O操作的作用。
One typical type of complex queries in MapReduce is queries on multiple occurrences of the same table, including self-joins.
下面一个SQL是论文中举的一个例子
SELECT sum(l_extendedprice) / 7.0 AS avg_yearly
FROM (SELECT l_partkey, 0.2* avg(l_quantity) AS t1
FROM lineitem
GROUP BY l_partkey) AS inner,
(SELECT l_partkey,l_quantity,l_extendedprice
FROM lineitem, part
WHERE p_partkey = l_partkey) AS outer
WHERE outer.l_partkey = inner.l_partkey;
AND outer.l_quantity < inner.t1; 如果不考虑Map Join,hive会将其翻译成3个MR Job,第1个job计算第1个子查询中对lineitem表的group by操作,第2个job计算第2个子查询中lineitem表和part表的join操作,第2个job计算外层前两个临时表的join操作。
Job1: generate inner by group/agg on lineitem
Map:
lineitem -> (k:l_partkey, v:l_quantity)
Reduce:
calculate (0.2*avg(l_quantity)) for each (l_partkey)
Job2: generate outer by join lineitem and part
Map:
lineitem -> (k: l_partkey,
v:(l_quantity,l_extendedprice))
part -> (k:p_partkey,v:null)
Reduce:
join with the same partition (l_partkey=p_partkey)
Job3: join outer and inner
Map:
outer-> (k:l_partkey, v:(l_quantity,l_extendedprice))
inner-> (k:l_partkey, v:(0.2*avg(l_quantity)))
Reduce:
join with the same partition of l_partkey
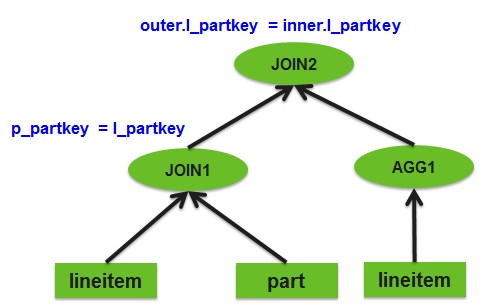
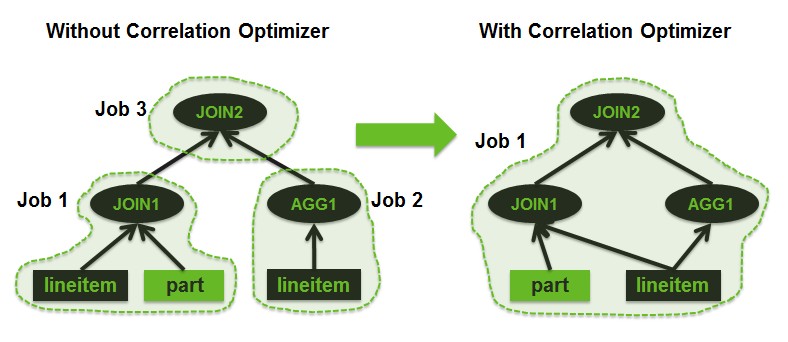
优化的思路非常简单Job1 与 Job2 都是按照相同表的相同字段lineitem.l_partkey进行shuffle,可以在一个job内完成,也不用读两次lineitem表。
Job3也是按照字段lineitem.l_partkey进行shuffle,在第一步合并之后的job中,已经是按照字段lineitem.l_partkey进行shuffle,因此job3也是没有必要的,也就很自然的将这3个job合并成一个job。
Job1: generate both inner and outer,
and then join them
Map:
lineitem -> (k: l_partkey,
v:(l_quantity,l_extendedprice))
part -> (k:p_partkey,v:null)
Reduce:
get inner: aggregate l_quantity for each (l_partkey)
get outer: join with (l_partkey=p_partkey)
join inner and outer 通过这个例子,可以总结出三种相关性:
–Input correlation (IC): independent operators share the same input tables.
–Transit correlation (TC): independent operators have input correlation and also shuffle the data in the same way (e.g. using the same keys)
–Job flow correlation (JFC): two dependent operators shuffle the data in the same way 看完上面的例子,其实核心思想非常简单,只有两点:
Eliminate unnecessary data loading
- Query planner will be aware what data will be loaded
- Do as many things as possible for loaded data
Eliminate unnecessary data shuffling
- Query planner will be aware when data really needs to be shuffled
- Do as many things as possible before shuffling the data again
13年,YIN HUAI去了Hortonworks,与hive团队一起将这篇论文实现。虽然核心思想很简单,但是真正要去实现这个优化,却没那么简单
需要做的事情有:发现相关性,变换Query Tree,common join与map join全都支持,引入新的Operator支持在Reduce阶段做尽可能多的事情。
具体的事情:
-
HIVE-1772 optimize join followed by a groupby
-
HIVE-3430 group by followed by join with the same key should be optimized
-
HIVE-2206 add a new optimizer for query correlation discovery and optimization
…
非常欣赏和羡慕这样一个人,他既能写出论文,又能花时间将自己的论文实现,并且能make a didfference。
TODO 代码学习
参考:
HIVE-2206 add a new optimizer for query correlation discovery and optimization
HIVE-3667 Umbrella jira for Correlation Optimizer
http://www.slideshare.net/YinHuai/hive-correlation-optimizer
http://www.cse.ohio-state.edu/hpcs/WWW/HTML/publications/papers/TR-11-7.pdf