Vertical Pod Autoscaler的推荐算法深受Google Borg Autopilot的moving window推荐器的启发,moving window推荐器的原理可以看下Autopilot论文。Vertical Pod Autoscaler的推荐器vpa-recommend为每个vpa对象的每个container创建存储cpu和memory使用值的decay histogram对象,定期从prometheus中拉取所有pod的资源使用情况,将container的usage写入histogram中。decay histogram的桶的大小是按照指数增长的,cpu第一个桶的大小(firstBucketSize)是0.01,memory是1e7,指数值ratio是1.05,第一个桶存储$[0..firstBucketSize)$的使用值的权重,则第n个桶的起始值是
\[value(n)=firstBucketSize*(1+ratio+ratio^2+...+ratio^{(n-1)}) = \frac{firstBucketSize*(ratio^n - 1)}{(ratio - 1)}\]每个使用值权重写入到histogram中的桶的位置是
\[index=floor(log_{ratio}(\frac{value*(ratio-1)}{firstBucketSize}+1))\]value代表当前的usage值,写入cpu histogram权重值是
\[weight=Max(cpuRequestCores, minSampleWeight)*2^{\frac{(time-begin)}{CPUHistogramDecayHalfLife}}\]其中minSampleWeight=0.1,begin是记录的第一个使用值的时间,time是当前usage的时间,默认CPUHistogramDecayHalfLife=24h。
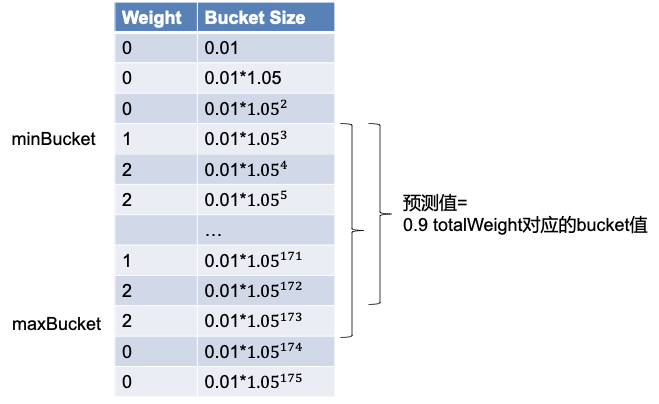
每次推荐的预测值即为0.9*totalWeight对应的桶的初始值,计算过程:从weight不为0的最小的桶开始将weight值相加,当结果大于等于0.9倍的totalWeight后,取这个桶的初始值作为推荐值。对于memory资源,vpa-recommend还会watch集群的oom事件,对于发生oom的pod,会自动增加预测值。
在大规模的使用中,Vertical Pod Autoscaler的性能有严重的问题。我们在一个3000+节点的集群使用VPA为3111+TApp进行预测时,发现批量创建VPA对象后过了几个小时,vpa-recommender仍然不停的打印调用scale API的日志,且无法为VPA对象推荐预测值。如果增大--kube-api-qps=1000 --kube-api-burst=2000可以解决这个问题,但是我们发现对于Custom resource definition的workload,vpa-recommender使用的scale http调用去解析VPA对象对应的workload和pod,该方法给apiserver带来3111*3/100的qps压力。所以我们修改了vpa-recommender的代码,增加了Custom resource的缓存解决了这个问题,社区觉得这个方案需要获取所有对象权限不安全,没有接受这个方案,但是实际使用中可以仅配置需要开启vpa的crd的权限即可。优化后效果提升显著,一次loop从需要花费1m41秒到1s就完成了,并且避免了给apiserver带来qps压力。社区最后采用了自己手写scale缓存的方法解决了这个问题。