docker swarm 项目开始于2014年,swarm是docker家的第一个容器集群项目。项目的核心设计是将几台安装docker的机器组合成一个大的集群,集群提供给用户的API接口与使用一台docker同样的接口。
swarmkit 项目开始于2016年,是docker家出的第二个容器集群项目,虽然也叫swarm,但是与第一个项目已经完全不同。该项目将docker engine内嵌了集群管理功能,新增了集群管理的用户接口。
两者可能实现了相同的功能,但其上层接口还是有很大的不同,docker推荐用户使用更适合自己的项目,如果都没有使用过,推荐使用后者。另外docker swarm项目并没有被docker公司列为deprecated项目,仍然会继续支持新的docker项目。
swarmkit核心设计
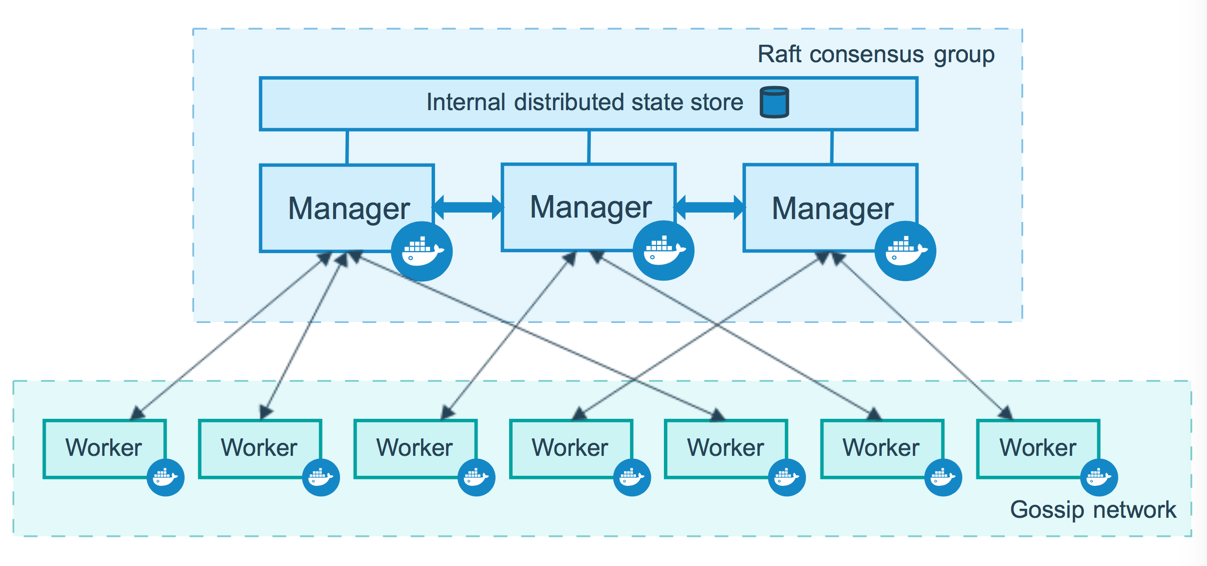
swarmkit项目目前的核心设计包括:
- Docker engine内嵌swarmkit提供集群管理,除了安装docker外无需其他软件,使用新增的docker swarm mode CLI管理集群
- 面向微服务,一个service包括多个task,每个task是一个container,task状态对等;
- 声明式的service状态定义,service的配置定义了所有task希望维持的状态
- 支持扩容缩容
- 自动容错,一个worker节点挂了,容器自动迁移到其他节点
- 支持灰度升级
- swarmkit所有节点对等,每个节点可选择转化为manager或者worker。manager节点内嵌了raft协议(基于etcd的raft协议)实现高可用,并存储集群状态
- 支持multi-host networking
- libnetwork实现集群网络
- 基于vxlan实现SDN
- 使用docker NAT访问外网
- 基于DNS server+lvs实现的服务发现和负载均衡
- 安全,每个节点使用对等的TLS相互通信,TLS证书是周期滚动的,由manager节点下发
swarmkit基本功能
创建集群
以3个节点为例,准备三台机器,这里使用docker machine进行说明。使用docker machine创建三台虚拟机,docker-machine会自动下载最新的1.12 boot2docker.iso,启动的虚拟机已经安装好docker1.12版本。
$ docker-machine create -d virtualbox manager1
$ docker-machine create -d virtualbox worker1
$ docker-machine create -d virtualbox worker2
$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
manager1 * virtualbox Running tcp://192.168.99.101:2376 v1.12.1
worker1 - virtualbox Running tcp://192.168.99.102:2376 v1.12.1
worker2 - virtualbox Running tcp://192.168.99.103:2376 v1.12.1
创建manager节点
切换到manager1节点,执行docker swarm init --advertise-addr <MANAGER-IP>创建新的swarm集群,manager1节点的docker成为swarm manager角色。
# 切换到manager1的docker环境
eval $(docker-machine env manager1)
$ docker swarm init --advertise-addr 192.168.99.101
Swarm initialized: current node (9p6hf9w8mnqkxzdby03si4b22) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-06fg2v27725iy8le0aj13jfaywta7b7ua8blltln77bwzoil6e-bjvj2kyr88c8na67uz173kepc \
192.168.99.101:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
--advertise-addr参数定义manager节点使用192.168.99.101做为自己的IP。
使用docker info,docker node ls查看manager节点的状态
$ docker info
...
Swarm: active
NodeID: 9p6hf9w8mnqkxzdby03si4b22
Is Manager: true
ClusterID: 5umhbh08rzg11szvxd7eh9nba
Managers: 1
Nodes: 3
Orchestration:
Task History Retention Limit: 5
Raft:
Snapshot Interval: 10000
Heartbeat Tick: 1
Election Tick: 3
Dispatcher:
Heartbeat Period: 5 seconds
CA Configuration:
Expiry Duration: 3 months
Node Address: 192.168.99.101
...
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
9p6hf9w8mnqkxzdby03si4b22 * manager1 Ready Active Leader
创建worker节点
切换到worker1和worker2节点,创建worker
$ eval $(docker-machine env worker1)
$ docker swarm join --token SWMTKN-1-06fg2v27725iy8le0aj13jfaywta7b7ua8blltln77bwzoil6e-bjvj2kyr88c8na67uz173kepc 192.168.99.101:2377
This node joined a swarm as a worker.
$ eval $(docker-machine env worker2)
$ docker swarm join --token SWMTKN-1-06fg2v27725iy8le0aj13jfaywta7b7ua8blltln77bwzoil6e-bjvj2kyr88c8na67uz173kepc 192.168.99.101:2377
This node joined a swarm as a worker.
--token参数的值是从上一步创建manager节点的输出获取的,192.168.99.101:2377是manager节点的地址。如果没有保存上一步输出的token,可以切换到manager节点执行docker swarm join-token worker获取。
同样在manager节点使用docker node ls打印集群的节点状态。
$ eval $(docker-machine env manager1)
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
2p07afdsfe8tabwpz27sqlrlf worker2 Ready Active
9p6hf9w8mnqkxzdby03si4b22 * manager1 Ready Active Leader
cumt545vk2a10wagf026qiehm worker1 Ready Active
创建service
切换到manager节点,使用docker service create命令创建service
$ docker service create --replicas 1 --name helloworld alpine ping docker.com
6kai8eak653bhuaomofkni7kt
$ docker service ls
ID NAME REPLICAS IMAGE COMMAND
6kai8eak653b helloworld 1/1 alpine ping docker.com
--replicas参数指定创建一个保持运行的task。我们可以使用docker service inspect和docker service ps查看service的详细和简略信息
$ docker service inspect --pretty helloworld
ID: 6kai8eak653bhuaomofkni7kt
Name: helloworld
Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
ContainerSpec:
Image: alpine
Args: ping docker.com
Resources:
$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
en20bib4yn8jjkg61b8qnsbbd helloworld.1 alpine manager1 Running Running 11 minutes ago
扩容缩容service
使用docker service scale命令扩容或者缩容service
$ docker service scale helloworld=3
helloworld scaled to 3
$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
en20bib4yn8jjkg61b8qnsbbd helloworld.1 alpine manager1 Running Running 14 minutes ago
d9fpsza181dwuu3fx6weebki6 helloworld.2 alpine worker2 Running Preparing 5 seconds ago
b91vkmv2oqoavfzp1zs7n8xfd helloworld.3 alpine worker1 Running Preparing 5 seconds ago
删除service
使用docker service rm删除service
$ docker service rm helloworld
灰度升级
首先使用3.0.6版本的镜像创建一个3个task的redis service
$ docker service create \
> --replicas 3 \
> --name redis \
> --update-delay 10s \
> redis:3.0.6
4tip9e8p9us14s634ncbsv6y0
--update-delay参数配置service灰度升级的时间间隔,默认情况scheduler一次只升级一个task,可以同时使用--update-parallelism参数配置并发升级的task数
查看redis service是否已经启动
$ docker service inspect --pretty redis
ID: 4tip9e8p9us14s634ncbsv6y0
Name: redis
Mode: Replicated
Replicas: 3
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
ContainerSpec:
Image: redis:3.0.6
Resources:
使用docker service update将redis service升级到3.0.7版本,--image参数指定升级的版本
$ docker service update --image redis:3.0.7 redis
redis
$ docker service inspect --pretty redis
ID: 4tip9e8p9us14s634ncbsv6y0
Name: redis
Mode: Replicated
Replicas: 3
Update status:
State: updating
Started: 52 seconds ago
Message: update in progress
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
ContainerSpec:
Image: redis:3.0.7
Resources:
使用docker service ps查看redis service的升级前后的状态变化
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
721wjyobwdv4temqryifdb216 redis.1 redis:3.0.7 worker2 Running Running 3 seconds ago
54cbfx39xtttn0z5802gttc0j \_ redis.1 redis:3.0.6 manager1 Shutdown Shutdown about a minute ago
86rr3cnbqk7d5ib770r4ko3pd redis.2 redis:3.0.6 worker2 Running Running about a minute ago
cb9p34evyo51iya1p5hkc0ex6 redis.3 redis:3.0.6 worker1 Running Running 3 seconds ago
NAT网络
创建service时使用--publish参数配置容器NAT网络的端口映射
$ docker service create --name my_web --replicas 3 --publish 8080:80 nginx
1so3f1p7iphhj2ccxmvyin87l
$ docker-machine ssh manager1
docker@manager1:~$ curl http://192.168.99.101:8080
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
</html>
overlay network
使用docker network create创建overlay网络,操作命令与docker engine相同
$ docker network create --driver overlay my-network
5yg4chi6b6xj8dsb0bi8zl0vw
创建service时使用--network参数配置容器需要加入的overlay网络
$ docker service create --replicas 3 --network my-network --name my-web nginx
默认情况下,将service接入overlay网络时,swarm会给service分配一个VIP,VIP与一个包含service名称的DNS记录形成映射关系,这个service的所有container共享这条DNS记录,swarm也会创建一个load balance将访问VIP的流量均衡到所有的task上。
我们启动一个另一个service还是加入my-network网络
$ docker service create --name my-busybox --network my-network busybox sleep 3000
0urwetl5jfs9cphq7ggynja2y
$ docker service ps my-busybox
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
0urwetl5jfs9cphq7ggynja2y my-busybox.1 busybox manager1 Running Running 12 minutes ago
使用docker exec进入容器查询查询这个DNS记录。直接查询service名称的域名返回这个service的VIP,查询tasks.<service name>DNS记录返回所有task的IP
$ eval $(docker-machine env manager1)
$ docker exec -it my-busybox.1.0urwetl5jfs9cphq7ggynja2y sh
/ # nslookup my-web
Server: 127.0.0.11
Address 1: 127.0.0.11
Name: my-web
Address 1: 10.0.0.2
/ # nslookup tasks.my-web
Server: 127.0.0.11
Address 1: 127.0.0.11
Name: tasks.my-web
Address 1: 10.0.0.4 my-web.2.14hggmn6m8rucruo2omt8wygt.my-network
Address 2: 10.0.0.5 my-web.3.ehfb5ue134nyasq2g539uaa6g.my-network
Address 3: 10.0.0.3 my-web.1.5yzoighbalqvio4djic464a9j.my-network
/ # wget -O- my-web
Connecting to my-web (10.0.0.2:80)
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
drain worker节点
drain worker节点功能方便对节点做一些运维操作,比如换机器。首先查看上一步灰度升级后的redis service,有一个task在worker2节点上
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
721wjyobwdv4temqryifdb216 redis.1 redis:3.0.7 worker2 Running Running 5 minutes ago
54cbfx39xtttn0z5802gttc0j \_ redis.1 redis:3.0.6 manager1 Shutdown Shutdown 6 minutes ago
15vhgz93khpgt7aak2uwiikfq redis.2 redis:3.0.7 manager1 Running Running 4 minutes ago
86rr3cnbqk7d5ib770r4ko3pd \_ redis.2 redis:3.0.6 worker2 Shutdown Shutdown 5 minutes ago
a8pdozzumncwffbr7k69zzsdd redis.3 redis:3.0.7 manager1 Running Running 3 minutes ago
cb9p34evyo51iya1p5hkc0ex6 \_ redis.3 redis:3.0.6 worker1 Shutdown Shutdown 3 minutes ago
使用docker node update命令对worker2节点进行下线操作
$ docker node update --availability drain worker2
worker2
使用docker node inspect命令查看worker2节点的可用性处于drain状态,scheduler会把drain状态节点上的task迁移到其他节点
$ docker node inspect --pretty worker2
ID: 2p07afdsfe8tabwpz27sqlrlf
Hostname: worker2
Joined at: 2016-09-19 07:13:53.507177094 +0000 utc
Status:
State: Ready
Availability: Drain
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 995.9 MiB
Plugins:
Network: bridge, host, null, overlay
Volume: local
Engine Version: 1.12.1
Engine Labels:
- provider = virtualbox
稍等片刻观察task的迁移状况,可以发现之前运行在worker2节点的redis.1 task已经迁移到worker1节点了
$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR
77digxshezgp1v5k4pfxzl863 redis.1 redis:3.0.7 worker1 Running Preparing 21 seconds ago
721wjyobwdv4temqryifdb216 \_ redis.1 redis:3.0.7 worker2 Shutdown Shutdown 21 seconds ago
54cbfx39xtttn0z5802gttc0j \_ redis.1 redis:3.0.6 manager1 Shutdown Shutdown 7 minutes ago
15vhgz93khpgt7aak2uwiikfq redis.2 redis:3.0.7 manager1 Running Running 4 minutes ago
86rr3cnbqk7d5ib770r4ko3pd \_ redis.2 redis:3.0.6 worker2 Shutdown Shutdown 6 minutes ago
a8pdozzumncwffbr7k69zzsdd redis.3 redis:3.0.7 manager1 Running Running 4 minutes ago
cb9p34evyo51iya1p5hkc0ex6 \_ redis.3 redis:3.0.6 worker1 Shutdown Shutdown 4 minutes ago
active worker节点
active worker节点可以重新将drain node恢复为可用节点
$ docker node update --availability active worker2
worker2
$ docker node inspect --pretty worker2
ID: 2p07afdsfe8tabwpz27sqlrlf
Hostname: worker2
Joined at: 2016-09-19 07:13:53.507177094 +0000 utc
Status:
State: Ready
Availability: Active
Platform:
Operating System: linux
Architecture: x86_64
Resources:
CPUs: 1
Memory: 995.9 MiB
Plugins:
Network: bridge, host, null, overlay
Volume: local
Engine Version: 1.12.1
Engine Labels:
- provider = virtualbox
promote/demote节点
promote/demote命令可以对节点的角色进行管理,方便对manager节点进行容灾处理。
docker node promote命令将worker节点转变为manager节点
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
14e2n6kebft5hs8arc5njm7ti * manager1 Ready Active Leader
aqbfvym02d85exu7i8th9yklo worker1 Ready Active
bjfb223324jjle3fprhvxg7of worker2 Ready Active
$ docker node promote worker1
Node worker1 promoted to a manager in the swarm.
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
14e2n6kebft5hs8arc5njm7ti * manager1 Ready Active Leader
aqbfvym02d85exu7i8th9yklo worker1 Ready Active Reachable
bjfb223324jjle3fprhvxg7of worker2 Ready Active
docker node demote命令将manager节点转变为worker节点
$ docker node demote worker1
Manager worker1 demoted in the swarm.
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
14e2n6kebft5hs8arc5njm7ti * manager1 Ready Active Leader
aqbfvym02d85exu7i8th9yklo worker1 Ready Active
bjfb223324jjle3fprhvxg7of worker2 Ready Active
退出swarm mode
使用docker swarm leave命令可以将节点的docker engine将退出swarm状态
$ docker swarm leave
Node left the swarm.