本篇是Autopilot: workload autoscaling at Google垂直自动缩放论文的翻译,第3.2节为全文翻译,第4节-第7节为重点归纳。
3 Autopilot自动调整限制值
3.2 垂直(每任务)自动缩放
Autopilot服务根据要自动缩放的资源是内存还是CPU,来选择要用于作业的推荐程序;作业对资源不足事件的容忍程度(容忍延迟与否,OOM敏感与OOM容忍);以及可选的用户输入(其中可能包括明确的推荐者选择)或其他参数来控制Autopilot的行为,例如可以设置的限制的上限和下限。
3.2.1 预处理:汇总输入信号
推荐者使用预处理的资源使用信号。大部分预处理是由我们的监控系统完成的,以减少历史数据的存储需求。聚集信号的格式类似于[35]中提供的数据。
| 符号 | 含义 |
|---|---|
| $r_i[τ]$ | 每个任务的CPU / MEM原始时间序列(1s分辨率) |
| $s_i[t]$ | 按任务汇总的CPU / MEM时间序列(直方图,5分钟分辨率) |
| $s[t]$ | 按作业的汇总CPU / MEM时间序列(直方图,5分钟分辨率) |
| $h[t]$ | 每个作业负载调整后的直方图 |
| $b[k]$ | 直方图的第k个边界值 |
| $w[τ]$ | 老化样品的权重τ |
| $S[t]$ | t时的移动窗口推荐值 |
| m | 一个模型(参数化的arg min算法) |
| $d_m$ | 模型m使用的衰减率 |
| $M_m$ | 模型m使用的安全边界值 |
| L | 推荐系统测试的限制值 |
| $L_m[t]$ | 模型m推荐的限制值 |
| $L[t]$ | ML推荐器的最终推荐值 |
| $o(L)$ | 超出限制值L的成本 |
| $u(L)$ | 未超出限制值L的成本 |
| $w_o$ | 超出限制值成本的权重 |
| $w_u$ | 未超出限制值成本的权重 |
| $w_{ΔL}$ | 改变限制值的惩罚权重 |
| $w_{Δm}$ | 改变模型的惩罚权重 |
| d | 模型成本计算时的衰减率 |
| $c_m[t]$ | 模型m的(已减少)历史成本 |
低级任务监视记录的原始信号是针对作业的每个任务的测量值的时间序列(例如,CPU或RAM的使用情况,或接收到的查询数量)。我们表示监视系统在𝜏时刻记录的i任务的值为$r_i[τ]$。该时间序列通常每1秒包含一个样本。
为了减少在设置作业资源限制时存储和处理的数据量,我们的监视系统将$r_i[τ]$预处理为汇总信号$s[t]$,通常为5分钟窗口内的汇总值。单个聚集信号样本$s[t]$是一个直方图,总结了这5分钟内所有工作任务的资源使用情况。
更正式地,对于每个窗口,聚合的每任务信号$s_i[t]$是一个矢量,将原始信号$r_i[τ] τ∈t$保存为直方图。
对于CPU信号,此向量的元素$s_i[t][k]$将原始信号样本$r_i[τ]$的数量分为约400个使用量桶:
\[S_i[t][k] = |{r_i[τ] : τ ∈ t ∧ b[k−1] ≤ r_i[τ] < b[k]}\]其中$b[k]$是第bucket个桶的边界值(这些值由监视系统固定)。对于内存信号,我们在直方图中仅记录5分钟窗口内任务的峰值(最大)请求(即每个任务的直方图$s_i[t][k]$只有一个非零值)。内存信号使用峰值而不是整个分布,因为我们通常希望提供(接近)峰值内存的使用率:与CPU(仅受CPU限制)相比,任务对内存不足的配置(因为它将以OOM终止)更加敏感。
然后,我们将每任务的直方图$S_i[t]$汇总到一个每作业的直方图$s[t]$只需将相加即可得出单个作业直方图$s[t][k] = Σ_is_i[t][k]$ 由于大多数Borg作业中的单个任务是可互换的副本,因此除少数特殊情况外,我们对所有任务都使用相同的限制。
3.2.2 移动窗口推荐器
移动窗口推荐器通过使用聚集信号𝑠的统计信息来计算限制值。
我们希望限制随着使用量的增加而迅速增加,但要在负载减少后缓慢降低,以避免对工作量暂时下降的过快响应。为了平滑对负载尖峰的响应,我们通过指数衰减权重$weight[τ]$对信号进行加权:
\[w[τ] = 2^{-τ/t_{1/2}}, (1)\]其中τ是样本寿命,而$t_{1/2}$是半衰期:权重减少一半的时间。Autopilot适合长时间运行的作业:我们将CPU信号的半衰期设为12小时,将内存信号的半衰期设为48小时。
使用以下有关的统计信息之一来计算时间t的推荐$S[t]$:
-
峰值($S_{max}$)返回最近采样的最大值:
\[S_{max}[t]=max_{τ∈{t-(N-1),...,t}}\{b[j]:s[τ][j]>0\}\]即最近N个样本中非空桶的最大值,其中N是固定的系统参数
-
加权平均值 ($S_{avg}$) 计算平均信号值的时间加权平均值:
\[S_(avg)[t]=\frac{Σ^∞_{τ=0}w[τ]\overline{s[t-τ]}}{Σ^N_{τ=0}w[τ]},(2)\]其中$\overline{s[τ]}$是直方图$s[τ]$的平均使用值,即 $\overline{s[τ]}=\frac{(Σ_j(b[j]s[τ][j]))}{(Σ_js[τ][j])}$。
-
j-%ile调整使用量百分数$S_{pj}$首先计算负载调整后的衰减直方图$h[t]$,其第k个元素$h[t][k]$将存储桶𝑘中的衰减样本数乘以负载$b[k]$:
\[h[t][k]=b[k] \cdot Σ^∞_{τ=0}w[τ] \cdot s[t-τ][k],(3)\]然后返回该直方图的某个百分位数$P_j(h[t])$。 h与标准直方图s的区别在于,在s中,每个样品都具有相同的单位权重,而在h中,存储桶k中的样品权重等于负载$b[k]$。
请注意,负载调整后使用率$S[p][j]$的给定百分位数可能会随时间的变化而与相同的使用率百分位数显著不同。在许多情况下,我们要确保在设置限制以适应所提供的负载时可以满足所提供负载的给定百分位数,而不是简单地计算瞬时观测到的负载可以处理的次数–即,我们希望根据负载而不是样本数量来加权计算。 这种差异如图2所示: 如果将限制值设置为1(时间的90%),则最后一个时刻的9/19单位负载将超过极限(下虚线)。在这种情况下,负载调整后的直方图

h的计算如下。由负载调整后的直方图h计数的单个观测值可以解释为在特定负载(信号的当前水平)下处理的信号区域的单位。 h等于h[1] = 1·9(9个时间单位内的负载1)和h[10] = 10·10(1个时间单位内的10负载)。 因此,h的90%,或者使90%的信号区域以该限制或低于该限制进行处理,为10 – 在这种情况下,意味着可以在限制范围内处理整个信号。
Autopilot根据信号和作业类别使用以下统计信息。对于CPU限制,我们使用:
- 批处理作业:$S_{avg}$,表示平均值,因为如果一项作业可以承受CPU节流,则对基础结构的最有效限制是该作业的平均负载,这使该作业得以继续进行而不会累积延迟。
- 服务作业:根据负载对延迟的敏感度,按负载调整后的使用率分别为$S_{p95}$(95%ile)或$S_{p90}$(90%ile)
对于内存,Autopilot根据作业的OOM容忍度使用不同的统计信息。对于大多数大型作业,默认设置为“低”,对于小型作业,默认设置为“最小”(最严格),但可由用户覆盖:
- OOM容忍度低的作业使用$S_{p98}$。
- OOM容忍度最低的作业使用$S_{max}$。
- 对于具有中等OOM容忍度的作业,我们选择值以(部分)覆盖短负载峰值; 我们通过使用$S_{p60}$的最大值(加权的60%ile)和峰值的一半$0.5S_{max}$来做到这一点。
最后,这些原始推荐值在应用之前会先进行处理。首先,建议增加10%至15%的安全阈值(对于较大的限制值会小一些)。然后我们 采取最近一个小时内看到的最大推荐值,以减少波动。
3.2.3 机器学习推荐器
原则上,Autopilot解决了机器学习问题:针对一项作业,根据其过去的使用情况,找到一个限制,可以优化表示该工作和基础架构目标的功能。上一节中描述的方法(基于对移动窗口的简单统计来设置限制)指定了解决此问题的算法。 相比之下,Autopilot的ML推荐器从成本函数(所需解决方案的规格)开始,然后为每个工作选择合适的模型参数以优化此成本函数。这样的自动化使Autopilot可以为每个作业优化移动窗口推荐器为所有作业设置的固定的参数,例如衰减率$t_{1/2}$,安全阈值或缩减稳定期。
ML推荐器由许多模型组成。推荐器会定期为每个工作选择效果最佳的模型(根据下面定义的成本函数,再根据历史使用情况进行计算);然后由所选模型负责设置限制。每个模型都是简单的arg min类型算法,可最大程度地降低成本–模型因分配给arg min各个元素的权重而异。机器学习方法反复出现的问题之一是其结果的可解释性[8]:Autopilot推荐器设置的限制值必须向作业的负责人解释。拥有许多简单的模型有助于解释ML推荐器的行为:单个模型大致对应于推断出的作业特征(例如,花费长时间才能稳定的模型对应于利用率变化迅速的工作)。然后,考虑到所选模型所施加的权重,其决策很容易解释。
更正式地说,对于信号s,在t时刻,ML推荐器从一组模型{m}中选择一个模型m[t]用于推荐限制值。模型是参数化的arg min算法,可根据历史数据计算限制值。模型m由衰减率$d_m$和安全边界值$M_m$参数表示。
在每个瞬时t,模型都会测试所有可能的限制值L(可能的限制值对应于直方图桶的边界L∈{𝑏[0],…,𝑏[𝑘]})。对于每个限制值L,该模型都会根据最近的使用直方图s[t]计算出未超限和超限的当前成本,然后用历史值对其进行指数平滑。超限成本O(𝐿)[t]计算最近直方图中超出限制L的存储桶中的样本数:
\[O(𝐿)[t] = (1−d_m)(o(L)[t−1])+d_m(Σ_{j:b[j]>L}s[t][j]). (4)\]同样,未超限成本u(L)[t]计算低于限制值L的存储桶中的样本数,
\[u(L)[t] = (1−d_m)(u(L)[t-1])+d_m(Σ_{j:b[j]<L}s[t][j]) . (5)\]然后,模型选择限制值$L’_m[t]$,以使限制值的可能变化最小化未超限,超限和惩罚$Δ(L,L’[t-1])$的加权和:
\[L'_m[t] = arg min_L(w_oo(L)[t]+w_uu(L)[t]+w_{ΔL}Δ(L,L'_m[t−1]) ,(6)\]其中如果$x≠y$,则$Δ(x,y)=1$,否则为0。(如果用克罗内克δ函数表示,$Δ(x,y) = 1-δ_{x,y}$)
这个函数涵盖了在大型系统中做资源分配决策的三个关键成本。超限表示损失机会的成本–在服务型作业中,发生超限时查询会延迟,这意味着某些最终用户可能不太愿意继续使用系统。未超限表示浪费基础设施的成本:作业储备的资源越多,所需的电力,机器和人员就越多。惩罚项Δ有助于避免过于频繁地更改限制,因为这可能导致任务不再适合其当前机器,从而导致其(或其他任务)被逐出。
最终,限制值将加上安全边界值$M_m$,即
\[L_m[t]=L'_m[t]+M_m. (7)\]为了在运行时选择模型(从而优化特定作业的衰减率$d_m$和安全边界值$M_m$),ML推荐器为每个模型维护其(指数平滑)成本$c_m$,它是超限,未超限和限制更改的惩罚值的加权和:
\[c_m[t]=d(w_oo_m(L_m[t],t)+w_uu_m(L_m[t],t)+ w_{Δ𝐿}Δ(L_m[t],L_m[t −1])) + (1−d)c_m[t−1].(8)\]由于历史成本包括在$c_m[t−1]$中,因此给定模型的$u_m$和$o_m$成本仅考虑最近的成本,即最后一个直方图样本中超出限制值的数量,因此$o_m(L_m[t],t)=Σ_{j:b[j]>L}s[t][j]$,$u_m(L_m[t],t)=Σ_{j:b[j]<L}s[t][j]$。
最后,推荐器选择一个模型以最大程度地降低此成本,但要更改限制值和模型会受到其他惩罚:
\[L[t] = arg min_m(c_m[t]+w_{Δm}Δ(m[t−1],m)+w_{ΔL}Δ(L[t],L_m[t])).(9)\]总体而言,该方法类似于多武装匪徒问题,其中匪徒的“手臂”与限制值相对应。 但是,多武装匪徒的关键特性是,一旦选择了一个分支,我们将无法观察到所有其他分支的结果。 相反,一旦知道下一个时间段的信号,Autopilot就可以计算所有可能极限值的成本函数-除非极少数情况下,使用的限制值太小并且任务以OOM终止(我们在4.3节中将介绍OOM其实很少见)。这种充分的可观察性使我们的问题变得更加容易。
集合具有五个超参数:上面定义的成本函数中的权重(d,$w_o$,$w_u$,$w_{ΔL}$和$w_{Δm}$)。这些权重大致对应于美元机会与美元基础设施成本。我们在离线实验中调整这些超参数,在此过程中,我们根据从代表性工作中获取的已保存数据的样本来模拟Autopilot的行为。此类调整的目的是要产生一种配置,该配置在大部分样本中占据替代算法(例如,移动窗口推荐器)的主导地位,并且具有类似(或略低)数量的超过限制和限制值调整,以及显著更高的资源利用率。这种调整是迭代的和半自动的:我们对权重的可能值进行参数扫描(详尽搜索)。然后手动分析异常值(表现异常差的作业)。如果我们认为该行为不可接受,则在下一次参数扫描的迭代中汇总结果时,我们会手动增加相应作业的权重。
这些离线实验使用原始的(未调整的)使用数据,即它们不尝试根据新设置的限制值来调整信号(例如,在OOM之后,应终止任务然后重新启动)。但是,对特定的作业,OOM或CPU节流的影响可能有所不同–对于某些作业,OOM可能会增加未来的负载(因为终止的任务的负载由其他任务接管),而对于其他任务,这可能会导致负载下降(当服务质量下降时,最终用户会下降)。实际上,这不是问题,因为使用情况调整事件很少发生,而且我们会持续监控生产中的Autopilot,在这种情况下,很容易发现过频繁的OOM等问题。
4 推荐效果
- 一个作业一天的Footprint是其所有任务平均限制值的和,反映了作业使用的基础设施成本
- 一个作业一天的相对松弛度(relative slack)是(限制值-使用值)/限制值
- 一个作业一天的绝对松弛度(absolute slack)是(限制值时间-使用值时间)/24/3600,如果算法的总绝对松弛为50,那么我们浪费的RAM数量等于50台计算机。实现绝对值的较小值是一个雄心勃勃的目标:它要求所有任务的限制几乎始终与使用相同。
- relative OOM rate是作业的一天内OOM数/一天内平均任务数,直接关系到用户需要增加多少任务才能弥补Autopilot增加的不可靠性
4.2 减少松弛度
autopilot作业的松弛度明显低于非autopilot作业
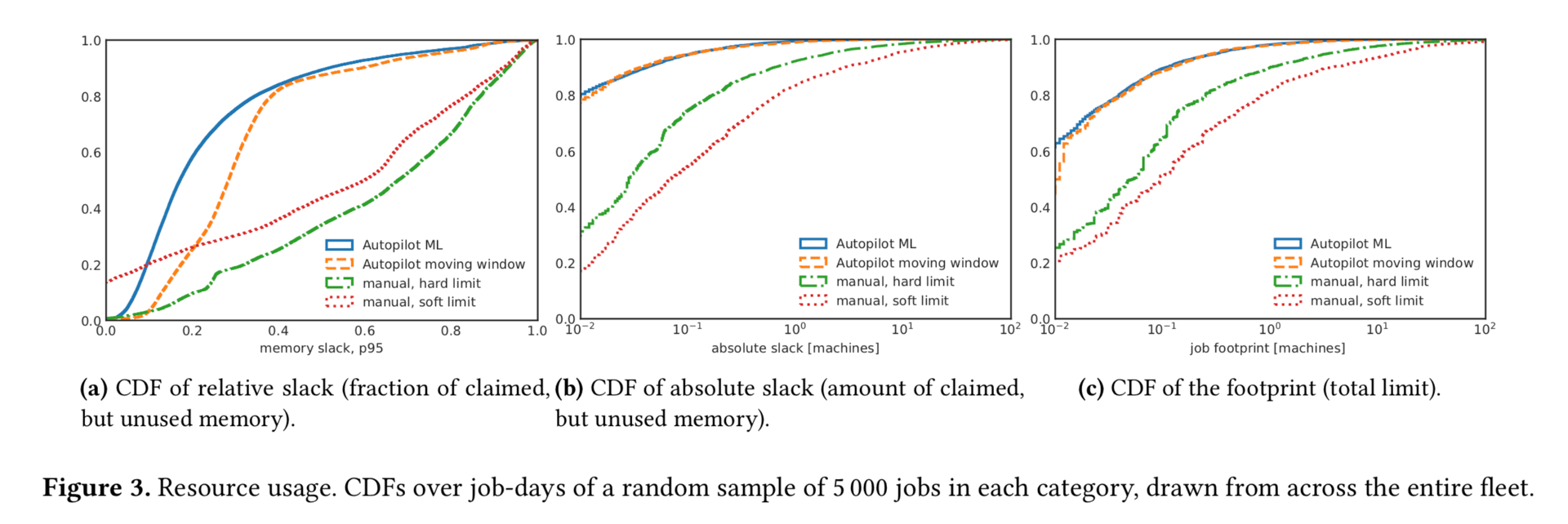
图3对比的是autopilot作业和非autopilot作业的松弛度
- 图3a显示了每个工作日的空闲时间的累积分布函数(CDF)。非autopilot作业的平均相对松弛度为60%(硬性限制)至46%(软性限制);而autopilot作业的平均相对松弛度为31%(移动窗口)至23%(ML)
- 图3b显示了样本中作业绝对松弛的累积分布函数。我们在10,000个非autopilot工作样本中的绝对总松弛量(按月平均)等于12,000多台机器;而autopilot作业样本的绝对松弛量少于500台计算机。差异相当于数千万美元的机器成本。
- 图3c显示了样本中作业对基础设施的使用量,可以看到autopilot作业使用的量远小于非autopilot作业。
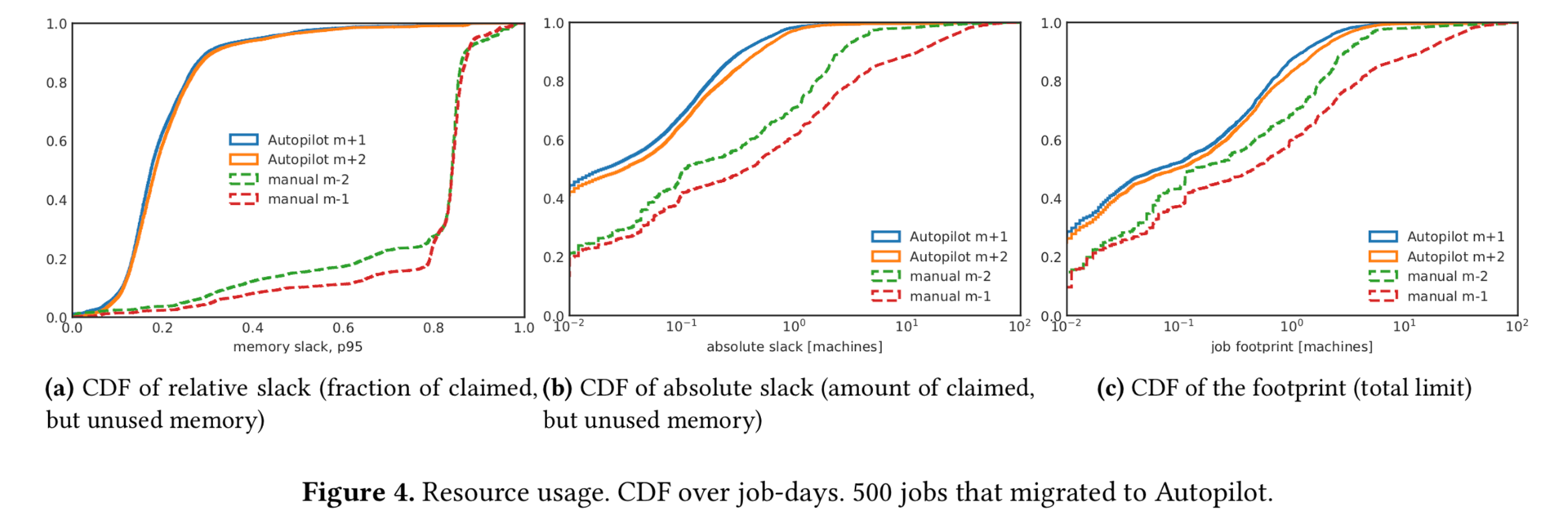
图4对比的是500个作业迁移到autopilot前后的松弛度
- 图4a显示了每个工作日相对松弛的CDF。迁移前一个月的平均相对松弛度为75%,中位数为84%。迁移后的一个月,平均相对松弛度下降到20%,中位数下降到17%。
- 绝对松弛度(图4b)表明可以节省大量资金:在迁移之前,这些作业浪费了相当于1870台计算机的RAM容量;迁移后,这些作业仅浪费了162台计算机:通过迁移这些作业,我们节省了1708台计算机的容量。
- 图4c显示了作业迁移前后对基础设施的使用量,迁移后使用量降低了,而且使用量增长速度也降低了
4.3 可靠性
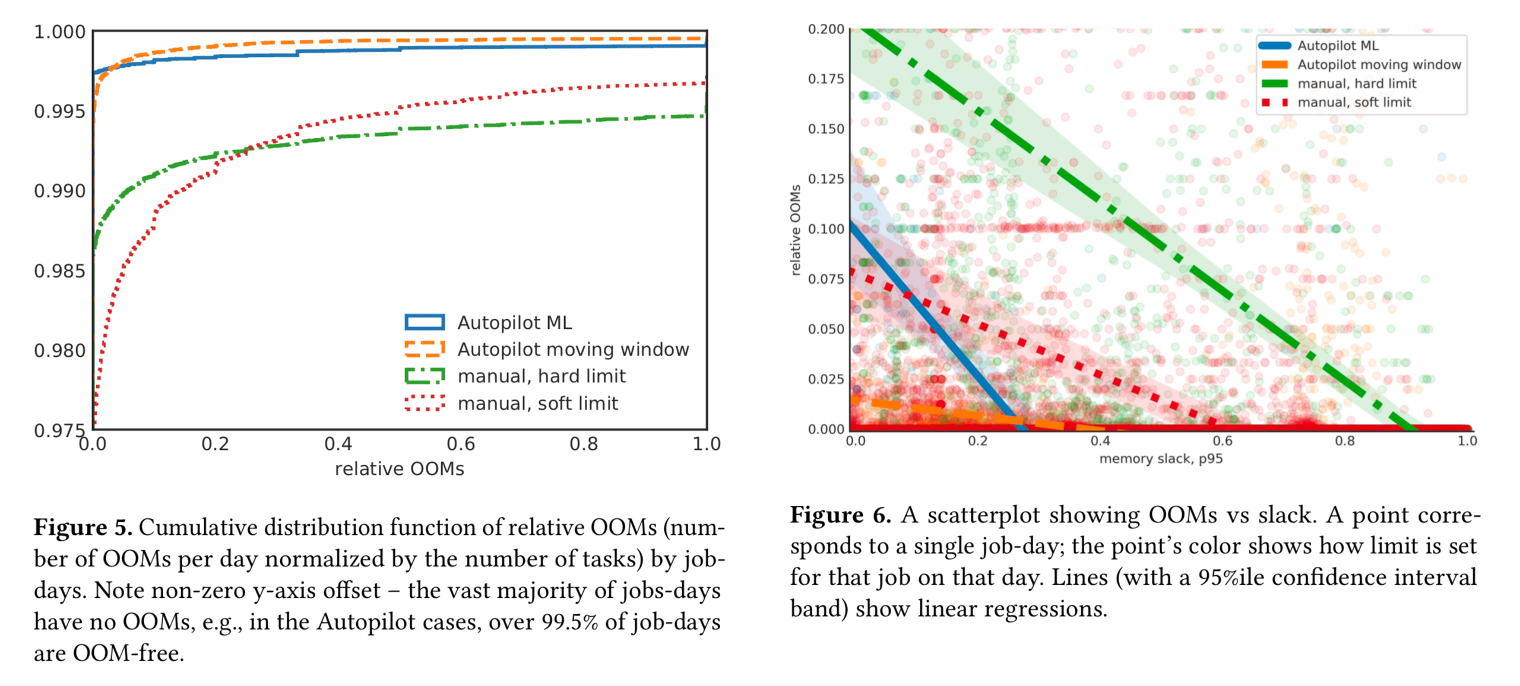
图5显示了按工作日划分的相对OOM的累积分布函数(CDF)。 OOM很罕见:超过99.5%的autopilot工作日没有OOM。虽然ML推荐器的无OOM工作日数比移动窗口推荐器略多,但它也导致相对OOM数略多(每任务日0.013比0.002)。 OOM的数量自然取决于相对的松弛度-较高的松弛度意味着更多的可用内存,因而能更少出现OOM。
图6中的线斜率表示OOM速率与松弛的相关程度,而截距则反映了OOM的总数。
4.4 限制值改变的次数
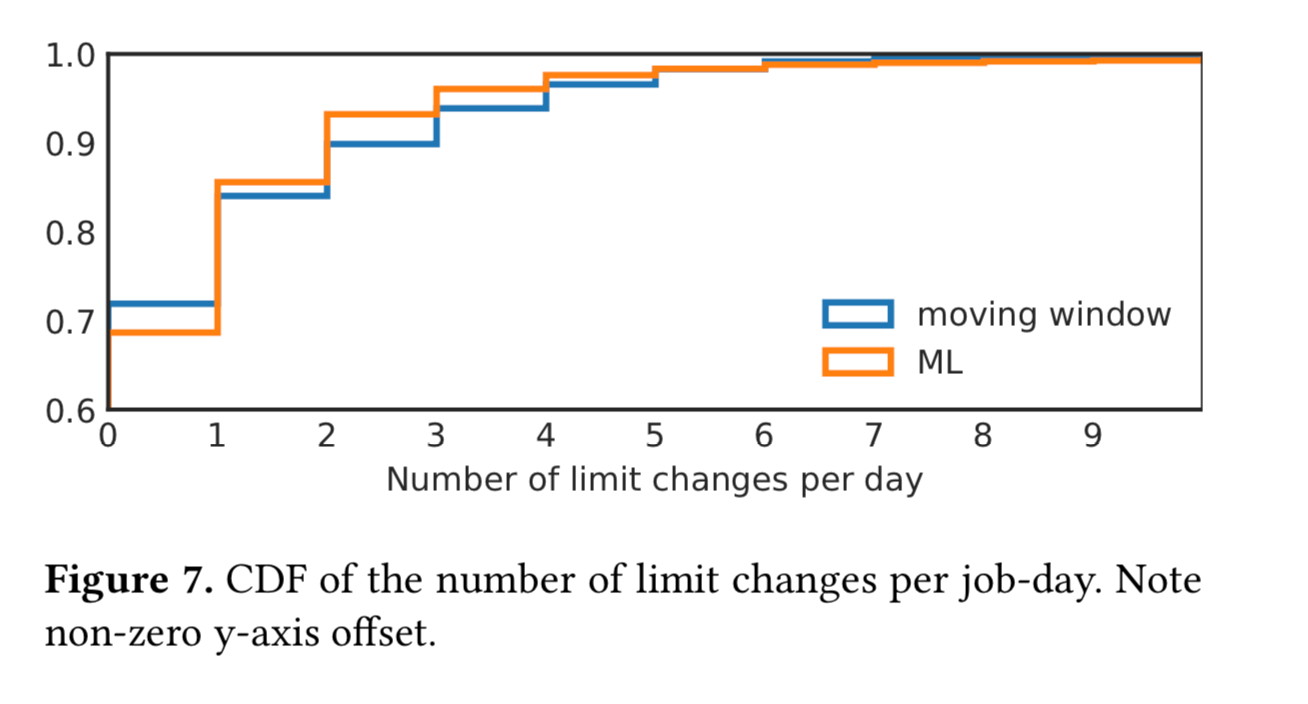
手动控制的工作很少会更改其限制:在我们的10 000个手动限制的工作样本中,我们观察到一个月内有334次变化,或每个工作日约0.001次变化。图7显示了autopilot更改10,000个工作样本限制值的频率:每个作业的频率比用户高出几百倍。但是,它仍然相当稳定:在大约70%的工作日中,没有任何变化。而99%ile的工作日一天内只有6(移动窗口)到7(ML)的限制变化。考虑到即使被逐出,找到任务的新位置通常只需要几十秒钟,那么为节省大量资金似乎是一个合理的价格。
4.5 行为随时间的变化
在前面的部分中,我们专注于长期运行的作业:我们的作业至少连续运行一个月。 在本部分中,我们将根据作业年龄来分析autopilot的性能。
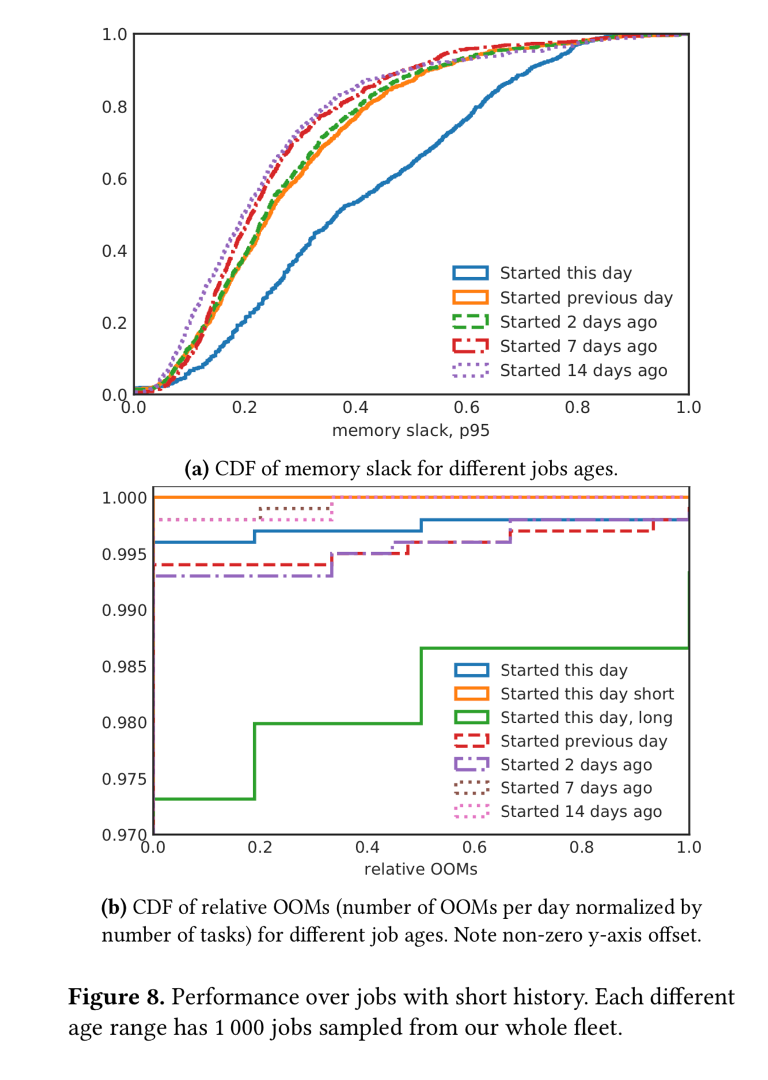
图8a显示了每个不同年龄段的1000个工作的相对松弛的CDF。 运行时间少于一天的作业比运行时间更长的作业具有更高的松弛度:这是autopilot针对长期运行的作业进行调整的直接结果–可用的历史越多,则松弛度越低
图8b对相对OOM速率的分析表明,autopilot对于短期工作非常谨慎。对于持续时间少于24小时的作业,几乎没有OOM:但是,如果我们过滤掉短期作业(总任务持续时间少于1.5小时的作业),则OOM会比稳定状态更多。一旦我们考虑了7天或更早之前开始的工作,相对OOM比率就可以与稳态行为相提并论。
5 使autopilot大量应用的关键特性
- 评估过程:根据历史数据进行空运行-A/B测试(一部分任务用autopilot)-分批灰度到所有任务
- 使用户可以方便的查看autopilot的限制数据
- 自动迁移到autopilot,一旦我们对大型离线模拟研究和较小规模的A / B实验对Autopilot的操作有了足够的信任,就可以将其作为所有现有小型作业的默认设置(总计最多限制10台机器)
6 减少工程劳动
Autopilot减少了手动调整资源值的工作量
- 水平缩放自动处理自然的负载增长。
- 垂直缩放既可以处理每个任务的负载变化,又可以处理推出新二进制文件带来的影响。
- 减少了必须由待命的dev / ops工程师处理的中断,可靠性的提高,任务失败的频率降低,监控系统发出的警报也更少
- 可能会暴露出一些程序的漏洞。当作业迁移到Autopilot之后开始频繁地开始进行OOM时,可能很难区分Autopilot的错误配置和真实的错误。一组人将此类问题归咎于Autopilot的内存限制,而仅在几周后才发现根本原因:很少触发的越界内存写操作。
- 用户甚至不必为作业指定资源限制,批处理作业会大量使用Autopilot(88%的作业启用了)。Autopilot作业占google资源使用量的48%以上。
7 相关工作
我们描述了两个推荐器:一个基于从移动窗口计算出的统计信息,其中包含窗口参数(如长度)由工作所有者设置(第3.2.2节);另一个根据成本函数自动选择移动窗口参数(第3.2.3节)。
这些简单统计的替代方法是使用更高级的时间序列预测方法,例如自回归移动平均(ARMA)(如[28]中也使用工作绩效模型),神经网络(如[ [18]],[9,20]中的递归神经网络或[13]中的自定义预测,这表明基于马尔可夫链的预测比基于自回归或自相关的方法表现更好。我们使用此类方法进行的初步实验表明,在绝大多数borg案例中,不需要ARMA的其他复杂性:作业倾向于使用较长的窗口(例如,移动窗口推荐器中内存的默认半衰期为48小时,第3.2.2节);并且日间趋势足够小,以至于一个简单的移动窗口能够迅速做出反应。